「構造化知識を使った言語処理応用」ワークショップ ~森羅2022最終報告会~
1月18日に「構造化知識を使った言語処理応用」ワークショップ ~森羅2022最終報告会~を開催します。参加申し込みはこちらからどうぞ。
参加申し込みはこちら!
2022年度の森羅プロジェクトは?
2022年度の森羅プロジェクト(森羅2022)では、協働による知識の構造化を目指し、Wikipediaの分類、属性値抽出、リンキングタスクを実施します。
タスク参加はこちら!
新着情報
- 1月18日に「構造化知識を使った言語処理応用」ワークショップ ~森羅2022最終報告会~を開催します。参加申し込みはこちらからどうぞ。(2022/12/23)
- 学生・若手研究者のためのBERTワークショップ2(固有表現抽出タスク)のページで2回目の資料(スライド、動画)を公開しました。(2022/11/3)
- 本評価(分類タスク)の提出締切が11月14日になりました。本評価の入力データ(JSONL)をダウンロードして、システムの予測結果をこちらからご提出ください。なお、属性値抽出とリンキングの2022年度の本評価は行いません。(2022/10/26)
- 10月27日に学生・若手研究者のためのBERTワークショップ2(固有表現抽出タスク、2日目)を開催します。参加申し込みはこちらからどうぞ。(2022/10/17)
- 学生・若手研究者のためのBERTワークショップ2(固有表現抽出タスク)のページで1回目の資料(スライド、動画)を公開しました。(2022/10/1)
- 9月30日と10月末に学生・若手研究者のためのBERTワークショップ2(固有表現抽出タスク)を開催します。参加申し込みはこちらからどうぞ。(2022/9/16)
- 学生・若手研究者のためのBERTワークショップのページで2回目の資料(スライド、動画)を公開しました。(2022/8/11)
- 学生・若手研究者のためのBERTワークショップのページで1回目の資料(スライド、動画)を公開しました。(2022/8/5)
- 8月4日、10日に学生・若手研究者のためのBERTワークショップを開催します。参加申し込みはこちらからどうぞ。(2022/7/20)
- 森羅2022キックオフミーティングを開催しました。タスク参加はこちらからどうぞ。(2022/5/12)
- 森羅プロジェクトが英国の雑誌Impactの記事として取り上げられました。どうぞご覧ください。(2022/2/24)
- 森羅2021の最終報告会(12月20日)にご参加いただき、ありがとうございました。資料を最終報告会ページに掲載していますので、どうぞご覧ください。(2021/12/24)
- LinkJPタスクのテストデータ正解を公開しました。(2021/11/15)
- MLタスクの実行結果の提出〆切を11月15日に延長しました。ぜひタスク参加をご検討下さい。(2021/10/4)
森羅チャンネル
今後も動画を公開していきます。チャンネル登録お願いします。
インタビュー

森羅プロジェクト紹介
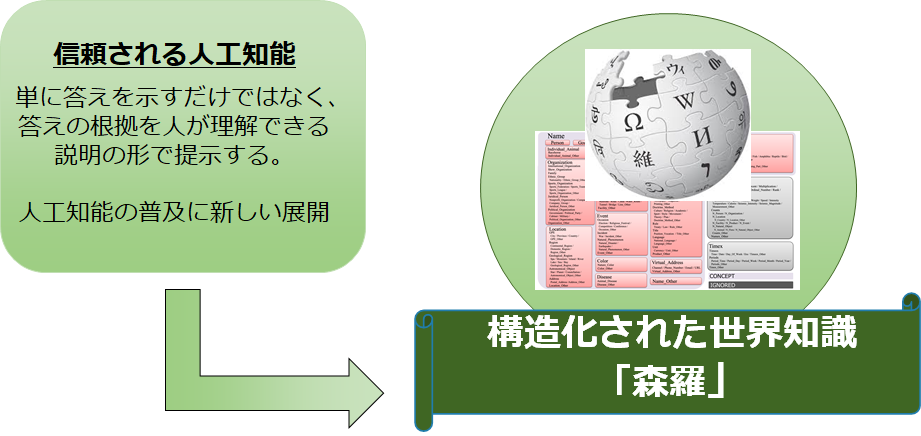
森羅プロジェクトは、 Wikipediaに書かれている世界知識を計算機が扱えるような形に変換することを目的として、Wikipediaを構造化するプロジェクトです。私達は、名前のオントロジーである「拡張固有表現(ENE)」にWikipediaの記事を分類し、拡張固有表現に定義されている属性情報をWikipedia記事にアノテーションし、対象Wikipediaページにリンクすることで、計算機利用可能な知識の構造化を目指しています。
構造化は3段階のステップにわけられます。
- Wikipedia項目のENEへの分類
(例:「島崎藤村」ページを「人名」に分類) - ENEで定義された属性に対応する属性値を抽出
(例:「人名」の「作品」という属性に対応する「嵐」を属性値として抽出) - 属性値を、それに対応するWikipediaページに紐づけ
(例:属性値「嵐」をWikipediaページの「嵐(小説)」に紐づけ)
森羅プロジェクトは、様々なアプローチによる多数のシステムを評価型ワークショップを開催することで募り、それらを統合することで構造化データを構築する「Resource by Collaborative Contribution(協働による知識構築)」の考えに基づくプロジェクトです。
タスク概要
森羅プロジェクトは2017年にスタートしたリソース構築プロジェクトで、人が読むことを想定して書かれたWikipediaの知識を計算機が扱える形に構造化することを目指し、「協働によるリソース構築(Resource by Collaborative Contribution(RbCC))」という枠組みで、評価型タスクとリソース構築を同時に進めています。

日本語構造化タスクは森羅プロジェクトで2018年から実施している日本語Wikipediaを対象とした情報抽出タスクで、今回が4回目となります。
森羅2022ではこれまでの森羅プロジェクトのタスクを統合したEnd-to-Endタスクと、その構成要素となる3つのサブタスクを開催し、参加者を募集します。
End-to-Endタスクでは、以下の3つのステップを一気に実施することで、分類、属性抽出、リンクの複合タスクを実現し、相乗効果/End-to-Endで精度向上の可能性を探ります。

End-to-Endタスクの各ステップは過去の森羅プロジェクトと以下の関係にあります。
- ステップ1(分類)
- 日本語の分類システム(今回は30言語の分類は実施しません)
- ステップ2(属性値抽出)
- 日本語の属性値抽出:森羅2018、2019、2020-JP
- 全てのカテゴリーを実施(過去の森羅プロジェクトでは81カテゴリーのみ)
- ステップ3(リンクの紐づけ)
- 日本語の属性値に対してリンクを実施:森羅2021-LinkJP
- 7つのカテゴリーに対して
これらの、過去の「森羅データ」を教師として利用することで、以下のように(半)自動的に知識を更新し続ける仕組みが実現できると考えています。
- 森羅2019を教師としてW2021を(半)自動で構造化
- 森羅2021を教師としてW2023を(半)自動で構造化
- 森羅2023を教師としてW2025を(半)自動で構造化
- …
一方で、End-to-Endタスクの各ステップに焦点を当てたタスクとして以下の3つのサブタスクも開催し、サブタスクのみの参加も歓迎いたします。
- 分類タスク
- 属性値抽出タスク
- リンクタスク
多くの方のご参加をお待ちしています。
スケジュール
- キックオフミーティング&データ公開
2022年5月12日
- リーダーボードオープン
2022年5月12日
- 学生・若手研究者のためのBERTワークショップ
2022年8月4日,10日
- 学生・若手研究者のためのBERTワークショップ2
2022年9月30日,10月27日
- 第1回定期交流会
2022年10月27日
- 実行結果の提出締切
2022年11月14日
- 評価結果の返却
2022年11月30日
- 最終報告会
2022年12月中旬
- 第2回定期交流会
2022年12月中旬
コミュニティ/連絡先
メーリングリスト
shinra2022-all参加リンク
Slack
森羅2022:Wikipedia構造化プロジェクト(shinra2022.slack.com)参加リンク
Email(実行委員宛)
shinra2022-info (at) googlegroups.com
実行委員
委員長
関根 聡(理研AIP)
委員
野本昌子(理研AIP)中山功太(理研AIP/筑波大)隅田飛鳥(理研AIP)松田耕史(理研AIP/東北大)後藤美知子(理研AIP)宇佐美佑(Usami LLC)安藤まや(フリー)山田育矢(Studio Ousia/理研AIP)三浦明波(株式会社アティード)門脇一真(株式会社日本総合研究所)阪本浩太郎(株式会社BESNA研究所)渋木英潔(株式会社BESNA研究所)
関連研究
森羅プロジェクトに関する研究
- [Sekine2021b] Satoshi Sekine, Kouta Nakayama, Maya Ando, Yu Usami, Masako Nomoto and Koji Matsuda,
SHINRA2020-ML: Categorizing 30-language Wikipedia into fine-grained NE based on “Resource by Collaborative Contribution” scheme, In Proceedings of the 3rd conference on the Automated Knowledge Base Construction (AKBC 2021), 2021. - [Sekine2020b] Satoshi Sekine, Masako Nomoto, Kouta Nakayama, Asuka Sumida, Koji Matsuda, and Maya Ando,
Overview of SHINRA2020-ML Task, In Proceedings of the NTCIR-15 Conference.[slide], [poster] - [Bui2020] The Viet Bui and Phuong Le-Hong,
Cross-lingual Extended Named Entity Classification of Wikipedia Articles, In Proceedings of the NTCIR-15 Conference. - [Cardoso2020] Rúben Cardoso, Afonso Mendes and Andre Lamurias,
Priberam Labs at the NTCIR-15 SHINRA2020-ML: Classification Task, In Proceedings of the NTCIR-15 Conference. - [Abhishek2020] Tushar Abhishek, Ayush Agarwal, Anubhav Sharma, Vasudeva Varma and Manish Gupta,
Rehoboam at the NTCIR-15 SHINRA2020-ML Task, In Proceedings of the NTCIR-15 Conference. - [Yoshikawa2020] Hiyori Yoshikawa, Chunpeng Ma, Aili Shen, Qian Sun, Chenbang Huang, Guillaume Pelat, Akiva Miura, Daniel Beck, Timothy Baldwin and Tomoya Iwakura,
UOM-FJ at the NTCIR-15 SHINRA2020-ML Task, In Proceedings of the NTCIR-15 Conference. - [Nakayama2020b] Kouta Nakayama and Satoshi Sekine,
LIAT Team’s Wikipedia Classifier at NTCIR-15 SHINRA2020-ML: Classification Task, In Proceedings of the NTCIR-15 Conference. - [Yoshioka2020] Masaharu Yoshioka and Yoshiaki Koitabashi,
HUKB at SHINRA2020-ML task, In Proceedings of the NTCIR-15 Conference. - [Nishikawa2020] Sosuke Nishikawa and Ikuya Yamada,
Studio Ousia at the NTCIR-15 SHINRA2020-ML Task, In Proceedings of the NTCIR-15 Conference. - [Nakayama2020a] 中山功太, 栗田修平, 小林暁雄, 関根聡,
Pre-Distillation Ensemble:リソース構築タスクのためのアンサンブル手法, 言語処理学会第26回年次大会発表論文集, pp.375-378, 2020. - [Kobayashi2020] 小林暁雄, 中山功太, 安藤まや, 関根聡,
Wikipedia構造化プロジェクト「森羅2019-JP」, 言語処理学会第26回年次大会発表論文集, pp.1029-1032, 2020. - [Sekine2020a] 関根聡, 安藤まや, 小林暁雄, 隅田飛鳥,
拡張固有表現定義の更新と日本語Wikipedia分類データ2019, 言語処理学会第26回年次大会発表論文集, pp.1221-1224, 2020. - [Sekine2019b] Satoshi Sekine, Akio Kobayashi, Kouta Nakayama,
SHINRA: Structuring Wikipedia by Collaborative Contribution, In Proceedings of the 1st conference on the Automated Knowledge Base Construction (AKBC 2019), 2019. - [Sekine2019a] 関根聡, 小林暁雄, 安藤まや,
Wikipedia構造化プロジェクト「森羅2018」,言語処理学会第25回年次大会発表論文集, pp.69-72, 2019. - [Kobayashi2019] 小林暁雄, 中山功太, 関根聡,
森羅:Wikipedia構造化プロジェクト2018結果の分析と考察, 言語処理学会第25回年次大会発表論文集, pp.538-541, 2019. - [Hentona2019] 邊土名朝飛, 野中尋史, 小林暁雄, 関根聡,
外部知識源を使用したWikipediaからの化合物情報抽出, 言語処理学会第25回年次大会発表論文集, pp.791-794, 2019. - [Nakayama2019] 中山功太, 小林暁雄, 関根聡,
共有タスクにおけるGA重み付け加重投票を用いた属性値アンサンブル, 言語処理学会第25回年次大会発表論文集, pp.1547-1550, 2019.
その他の関連研究
- [Suzuki2018] Masatoshi SUZUKI, Koji MATSUDA, Satoshi SEKINE, Naoaki OKAZAKI and Kentaro INUI,
A Joint Neural Model for Fine-Grained Named Entity Classification of Wikipedia Articles‘, IEICE Transactions on Information and Systems, E101.D-1, pp.73-81, 2018. - [Sekine2018] 関根聡, 安藤まや, 小林暁雄, 松田耕史, 鈴木正敏, Duc Nguyen, 乾健太郎,
「拡張固有表現+Wikipedia」データ(2015 年 11 月版 Wikipedia分類作業完成版), 言語処理学会第24回年次大会発表論文集, pp.504-507, 2018. - [Sekine2002] Satoshi Sekine, Kiyoshi Sudo, and Chikashi Nobata,
Extended Named Entity Hierarchy. In Proceedings of the Third International Conference on Language Resources and Evaluation (LREC’02), 2002. - [Sekine2000] Satoshi Sekine and Yoshio Eriguchi,
Japanese Named Entity Extraction Evaluation – Analysis of Results –, In Proceedings of the 18th International Conference on Computational Linguistics (COLING’00), vol.2, pp.1106-110,
2000. - [Grishman1996] Ralph Grishman and Beth Sundheim,
Message Understanding Conference – 6: A Brief History, In Proceedings of the 16th conference on Computational linguistics (COLING’96), vol.1, pp.466-471, 1996.
タスク詳細

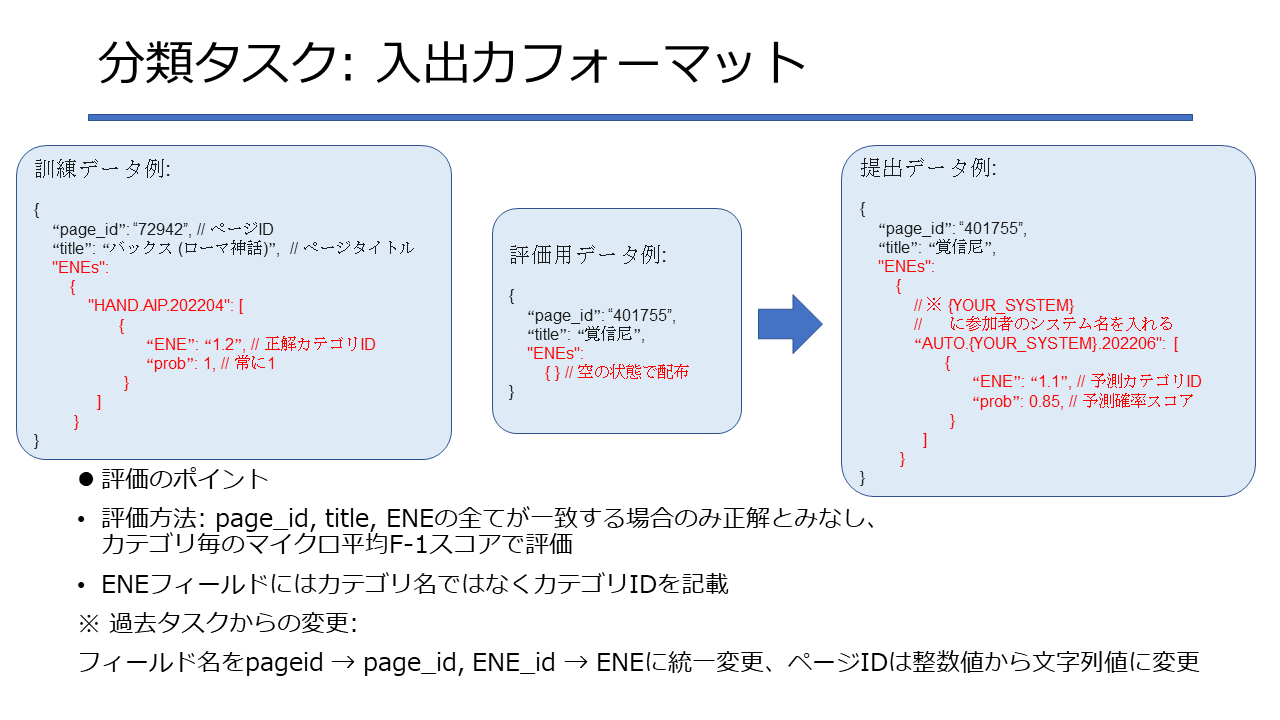 分類の対象カテゴリであるかは、拡張固有表現Ver.9.0(森羅タスク用)のchildren_categoryのリストを参照して確認します(リストが空なら末端カテゴリで分類対象となります)。
分類の対象カテゴリであるかは、拡張固有表現Ver.9.0(森羅タスク用)のchildren_categoryのリストを参照して確認します(リストが空なら末端カテゴリで分類対象となります)。
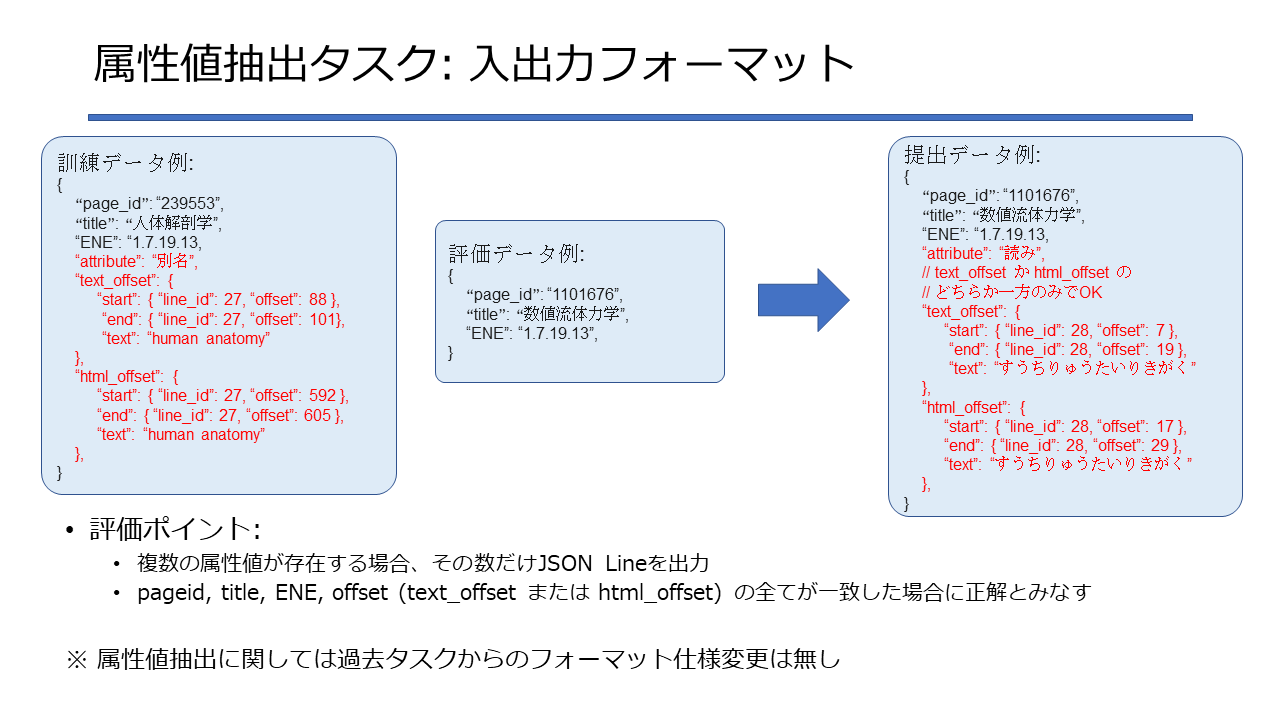 属性値抽出の対象属性であるかは、拡張固有表現Ver.9.0(森羅タスク用)のextraction_taskの値を参照して確認します。 2022年度の属性値抽出の評価について、本評価を行わず、リーダーボード評価のみとしました。
属性値抽出の対象属性であるかは、拡張固有表現Ver.9.0(森羅タスク用)のextraction_taskの値を参照して確認します。 2022年度の属性値抽出の評価について、本評価を行わず、リーダーボード評価のみとしました。
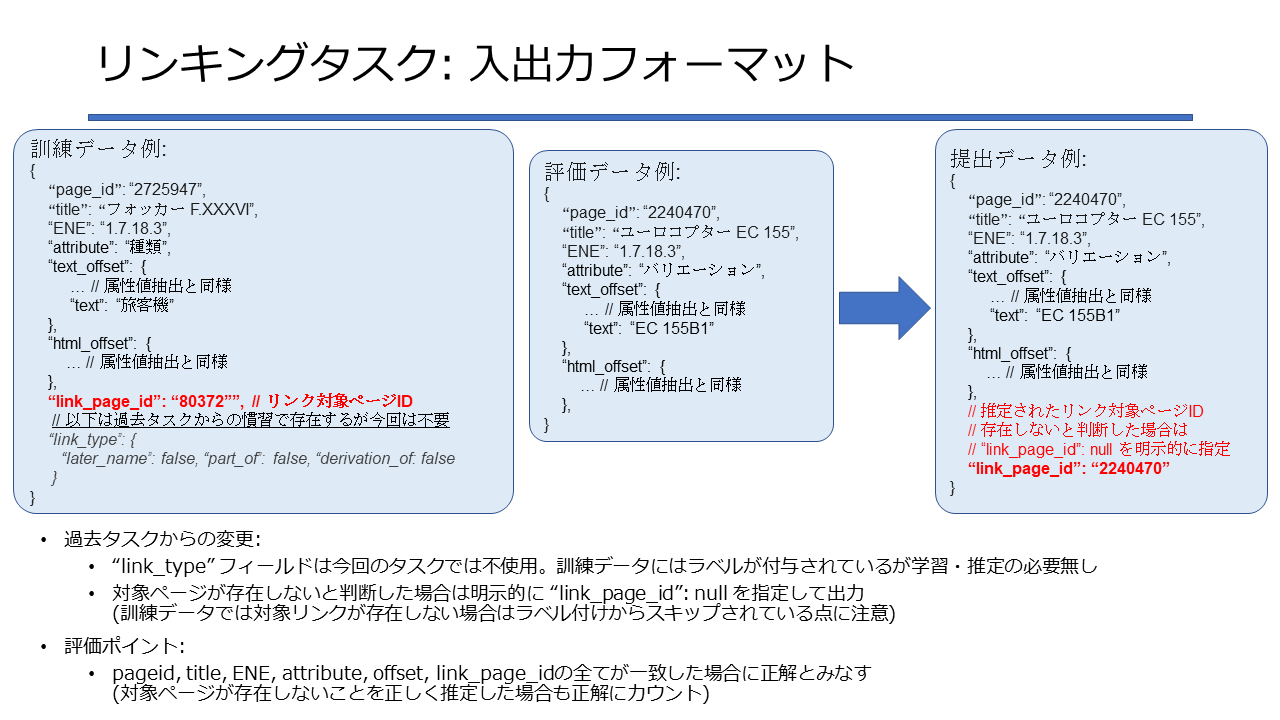 リンキングの対象属性であるかは、拡張固有表現Ver.9.0(森羅タスク用)のlinking_taskの値を参照して確認します。 2022年度のリンキングの評価について、本評価を行わず、リーダーボード評価のみとしました。
リンキングの対象属性であるかは、拡張固有表現Ver.9.0(森羅タスク用)のlinking_taskの値を参照して確認します。 2022年度のリンキングの評価について、本評価を行わず、リーダーボード評価のみとしました。FAQ
コミュニティ(Slack, メーリングリスト)について
- Q.プロジェクトのSlackはタスク参加者限定ですか?
- A.森羅のSlackはタスク参加の有無に関わらず、どなたでもご参加いただけます。 データセット、タスク等に関するアナウンスや議論を行い、ご質問も受け付けております。 プロジェクトにご興味のある方は、ぜひご参加ください。
プロジェクト/タスクへの参加について
- Q.タスクに参加するかどうか迷っています。いつまでに申し込めば良いですか?
- A.タスク参加について事前の申し込みは不要です。タスクの〆切までに実行結果を提出していただければ、参加とみなします。 プロジェクトのタスク関連のアナウンスはSlackとメーリングリストで行いますので、タスク参加が未定の場合もご参加ください。 タスク参加の流れについてはこちらをご覧ください。
- Q.プロジェクト参加には契約が必要ですか?(副業に該当しますか?)
- A.基本的にはプロジェクトへの参加による報酬はありません(学生の方のアルバイト等を除く)。 副業等には該当せず、特に契約は必要ありません。
- Q.タスクには賞金がありますか?
- A.賞金については予定しておりません。
- Q.個人でタスクに参加することは可能ですか?
- A.企業にお勤めの方が個人として参加を希望される場合、当プロジェクトとしては特に問題ありません。勤務先でご確認ください。
- Q.タスクに参加した場合、参加システムは公開する必要がありますか?
- A.公開は必須ではありませんが、もし可能でしたらご検討いただけるとありがたいです。
- Q.企業からの参加ですが、必ず発表しなければならないでしょうか?
- A.発表の義務はありません。
- Q.Wikipedia全件を対象にするとのことですが、計算機リソースに不安があります。
- A.計算機リソースなどについては相談に乗ります。Slack(招待リンク)などでお気軽にご相談ください。
- Q.リーダーボードへの参加は義務ですか?
- A.義務ではありませんが、ぜひご参加ください。
公開データについて
- Q.公開データを利用するには契約が必要ですか?
- A.プロジェクトとの契約は特に必要ありません。ただし、公開データはWikipediaの二次的著作物であり、クリエイティブ・コモンズ 表示・継承ライセンス(CC BY-SA 3.0)を継承することにご注意ください。
参考:Wikipedia:Wikipediaを二次利用する
データ利用による研究成果については森羅2022実行委員までお知らせいただけますよう、お願いいたします。
実行委員宛メール:shinra2022-info@googlegroups.com - Q.公開データを利用するにはタスク参加が必要ですか?
- A.タスクに参加されない場合も公開データの利用は可能です。タスク以外の研究等への利用もぜひご検討ください。
データの利用については「公開データを利用するには契約が必要ですか?」のQAもご確認ください。
データセット、タスク等に関するアナウンスや議論は森羅のSlackで行います。ご質問も受け付けておりますので、ぜひご参加ください。
過去の共有タスク
- SHINRA2021-MLタスク
- 30言語のWikipediaページを拡張固有表現に分類するタスクです。SHINRA2020-MLの継続で、さらなる精度向上を目指します。
- SHINRA2021-LinkJPタスク
- 森羅2021-LinkJPはエンティティーの属性値を該当するWikipediaページに紐づけるタスクです。
- SHINRA2020-MLタスク
- 30言語のWikipediaを拡張固有表現に分類するタスクです。トレーニングデータは分類された日本語Wikipediaの項目と日本語から各言語への言語間リンクを利用して作成します。日本語からの言語間リンクがないWikipediaページを分類するタスクです。
- 森羅2020-JPタスク
- 森羅2019に対し新たに施設名、イベント名の47種類の拡張固有表現カテゴリーを加えた82種類のカテゴリーについて、Wikipedia記事中の対応する記述部分にアノテーションを行うタスクです。
- 森羅2019-JPタスク
- 森羅2018に対し新たに組織名、地形名の30種類の拡張固有表現カテゴリーを加えた35種類のカテゴリーについて、Wikipedia記事中の対応する記述部分にアノテーションを行うタスクです。
- 森羅2018-JPタスク
- 5種類の拡張固有表現カテゴリーについて、それぞれのカテゴリーに分類されたWikipedia記事の文書中から、属性値を抽出する抽出タスクです。